In recent years, the field of machine learning has witnessed groundbreaking advancements that have reshaped the way we approach various tasks, from natural language processing to computer vision. Among these remarkable achievements, one paper, in particular, has had a profound impact on the field: “Attention Is All You Need.” Published in 2017 by Vaswani et al., this paper introduced the Transformer model, which brought attention mechanisms to the forefront of machine learning research. Since its release, the Transformer has become the backbone of numerous state-of-the-art models and has revolutionized the way we understand and utilize machine learning algorithms.
The Limitations of Recurrent Neural Networks
Before the advent of the Transformer model, recurrent neural networks (RNNs) were widely used for sequence-to-sequence tasks, such as machine translation or text summarization. RNNs process input sequentially, which limits their parallelization and makes them computationally expensive. Additionally, RNNs suffer from vanishing or exploding gradient problems, which hinder their ability to capture long-term dependencies in sequences. These limitations called for a novel approach that could overcome these issues and enable more efficient and accurate sequence modeling.
The Transformer Architecture
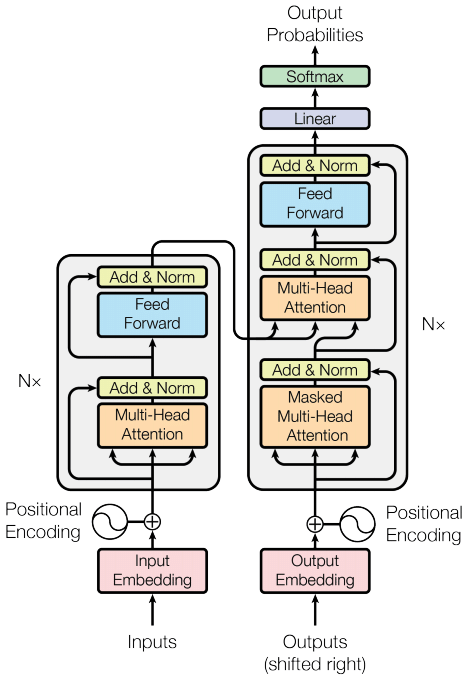
The “Attention Is All You Need” paper presented the Transformer, an attention-based neural network architecture that eliminated the need for recurrent or convolutional layers entirely. The key idea behind the Transformer is self-attention, a mechanism that allows the model to weigh the importance of different elements in a sequence when processing it.
The Transformer architecture consists of two main components: the encoder and the decoder. The encoder takes the input sequence and applies self-attention to capture the relationships between different elements in the sequence. The decoder, on the other hand, uses self-attention in combination with encoder-decoder attention to generate an output sequence based on the encoded representation. Crucially, self-attention allows the model to process the entire input sequence in parallel, making it highly efficient and significantly reducing the computational requirements.
Advantages and Impact
The introduction of the Transformer model brought several significant advantages and had a profound impact on the field of machine learning:
1. Parallelization: Unlike RNNs, the Transformer can process input sequences in parallel, resulting in faster training and inference times. This makes it particularly well-suited for handling long sequences and large-scale datasets.
2. Long-range dependencies: Self-attention enables the Transformer to capture long-range dependencies in sequences effectively. This ability to model relationships between distant elements is crucial for tasks such as machine translation, where words or phrases may have dependencies that span the entire sentence.
3. Scalability: The self-attention mechanism allows the Transformer to scale to much larger model sizes compared to traditional recurrent models. This scalability has paved the way for models with billions of parameters, such as GPT-3, which have achieved impressive results across various natural language processing tasks.
4. Generalizability: The Transformer’s attention mechanism makes it highly adaptable to different domains and tasks. It has been successfully applied to machine translation, language modeling, image recognition, speech synthesis, and many other areas, showcasing its versatility and effectiveness.
Conclusion
The publication of “Attention Is All You Need” and the introduction of the Transformer architecture marked a significant milestone in the field of machine learning. By leveraging self-attention, the Transformer model revolutionized the way we approach sequence modeling tasks, eliminating the need for recurrent layers and enabling parallel processing. Its advantages in terms of scalability, efficiency, and capturing long-range dependencies have led to state-of-the-art performance in various domains.
The impact of the Transformer extends far beyond the initial paper, as it has become the foundation for numerous subsequent models and techniques. It has not only advanced the field of natural language processing but has also influenced computer vision and speech.
Comments
7 responses to “AI Transformers – Attention Is All You Need”
This is a fantastic overview of the transformative impact the "Attention Is All You Need" paper has had on machine learning, especially through the introduction of the Transformer model. It’s fascinating to see how self-attention mechanisms have addressed the limitations of RNNs, such as parallelization and long-range dependency capturing. The scalability and versatility of the Transformer, allowing it to excel across various tasks and domains, truly highlight its revolutionary nature.
I’m curious about how you see the future evolution of Transformer-based models—what advancements or modifications do you think could further enhance their capabilities?
Hi Dexter,
Thank you for your thoughtful comment! The future of Transformer-based models certainly looks promising, and there are several exciting directions in which they might evolve. Here are a few potential advancements and modifications that could further enhance their capabilities:
Efficiency Improvements: As models scale up, the computational cost and memory requirements also increase. Researchers are actively working on more efficient variants of the Transformer, such as the Reformer and Linformer, which aim to reduce the computational complexity of the self-attention mechanism, making it more feasible to train large models on limited hardware.
Fine-Tuning and Transfer Learning: We might see further advancements in transfer learning techniques, allowing pre-trained Transformer models to be more easily adapted to various specific tasks with minimal additional training. This could make high-performance models more accessible for niche applications.
Integration with Other Architectures: Combining Transformers with other architectures, such as convolutional neural networks (CNNs) for vision tasks or graph neural networks (GNNs) for relational data, could unlock new potential. Hybrid models could leverage the strengths of multiple architectures to tackle a wider variety of problems more effectively.
Interpretable Models: One ongoing challenge with large Transformer models is their interpretability. Developing methods to better understand and visualize what these models are learning could lead to more transparent and trustworthy AI systems, which is crucial for sensitive applications like healthcare and finance.
Edge and Real-Time Applications: As efficiency improves, there is potential for deploying Transformer models in real-time or on edge devices. This could bring the power of sophisticated machine learning to applications requiring immediate responses, such as autonomous driving or real-time language translation.
Multimodal Transformers: Transformers that can handle and integrate multiple types of data, such as text, images, and audio, are already showing promise. Enhanced multimodal models could lead to more robust and versatile AI systems capable of understanding and generating content across different media.
Overall, the field is moving rapidly, and the versatility of the Transformer architecture suggests that it will continue to be a central component of future advancements in machine learning.
Best,
Maraya
Thank you for the insightful article on the transformative impact of the Transformer architecture in machine learning!
The shift from RNNs to Transformers indeed marked a significant leap forward, particularly in handling sequence-to-sequence tasks. The ability to process input sequences in parallel addresses the inherent inefficiencies of RNNs, offering both computational efficiency and the capability to model long-range dependencies effectively.
One relevant software engineering principle that aligns well with the success of Transformers is the Separation of Concerns. By decoupling the attention mechanism from the sequence processing, the Transformer architecture isolates the task of determining the importance of sequence elements (self-attention) from the sequence generation process. This modular approach not only makes the architecture more scalable and adaptable but also enhances maintainability and facilitates easier debugging and optimization.
Moreover, the Single Responsibility Principle (SRP) is exemplified in the design of the Transformer. Each layer or component of the Transformer has a well-defined role—whether it’s the self-attention mechanism, positional encoding, or the feed-forward layers—enabling focused improvements and innovations in each area without overhauling the entire system.
Overall, the Transformer architecture serves as a stellar example of how foundational software engineering principles can be applied to advance complex machine learning models, leading to robust, scalable, and high-performing systems.
This article beautifully encapsulates the transformational impact of the "Attention Is All You Need" paper and the subsequent rise of the Transformer model in machine learning. The shift from RNNs to Transformers has indeed been revolutionary, enabling more efficient and powerful models across various domains.
As T.S. Eliot once wrote, "Only those who will risk going too far can possibly find out how far one can go." This sentiment resonates profoundly with the pioneering spirit of Vaswani et al., who dared to rethink neural network architectures and, in doing so, have propelled the field to new heights.
The advantages of the Transformer, such as parallelization and scalability, have opened doors to innovations that were previously unimaginable.
What an insightful article on the transformative impact of the Transformer model in machine learning! The shift from recurrent neural networks to attention-based architectures truly exemplifies the continuous evolution in this field. As the article aptly highlights, the ability of Transformers to handle long-range dependencies and process sequences in parallel has opened up new possibilities for various applications.
It’s reminiscent of the words of Isaac Asimov: "I do not fear computers. I fear the lack of them." The advancements brought forth by models like the Transformer underscore the immense potential that innovative algorithms hold in advancing technology and solving complex problems. It’s exciting to think about what future breakthroughs may lie ahead as researchers continue to build upon this foundation!
This is a fantastic article that highlights the transformative impact of the "Attention Is All You Need" paper and the profound influence of the Transformer model on machine learning. The advantages of the Transformer, such as parallelization, scalability, and the ability to capture long-range dependencies, have indeed reshaped numerous domains.
It’s exciting to see how these advancements continue to push the boundaries of what’s possible with machine learning. Kudos to Vaswani et al. for their groundbreaking work!
Joke: Why did the Transformer model bring a ladder to the library? Because it wanted to reach new heights in understanding!
Thank you for the insightful summary of the Transformer model and its revolutionary impact on machine learning. The advancements brought by the "Attention Is All You Need" paper indeed mark a pivotal change in how sequence modeling tasks are approached.
From a legal perspective, especially for those involved in developing or deploying models based on the Transformer architecture, it’s crucial to consider the following:
Intellectual Property (IP) Issues: Ensure that any implementation or derivative work based on the Transformer model respects the intellectual property rights associated with the original paper by Vaswani et al. This includes adhering to the terms of any licenses under which the original work was published.
Data Privacy and Compliance: When utilizing these advanced models, particularly in sensitive applications such as healthcare or finance, one must ensure compliance with data protection regulations like GDPR in Europe or CCPA in California. This involves securing consent for data usage, ensuring data anonymization, and implementing robust security measures.
Bias and Fairness: The deployment of machine learning models must be scrutinized for potential biases. The inherent biases in training data can lead to unfair or discriminatory outcomes. Regular audits and the implementation of fairness-aware algorithms are essential to mitigate these risks.
Transparency and Explainability: Given the complexity of Transformer models, providing transparency and explainability of decisions made by these models is important, especially in regulated industries. Developing methods to interpret and explain the model’s decisions can help in building trust and ensuring accountability.
Ethical Considerations: Beyond legal compliance, ethical considerations should guide the development and deployment of machine learning models. This includes considering the broader societal impacts and ensuring that the technology is used for beneficial purposes.
By proactively addressing these legal and ethical aspects, developers and organizations can harness the power of Transformer models responsibly and effectively.